Essay
What OpenAI's goblin episode reveals about reward models
A compact case study in reward-model shortcuts and behavior transfer
By Robby Sneiderman. .
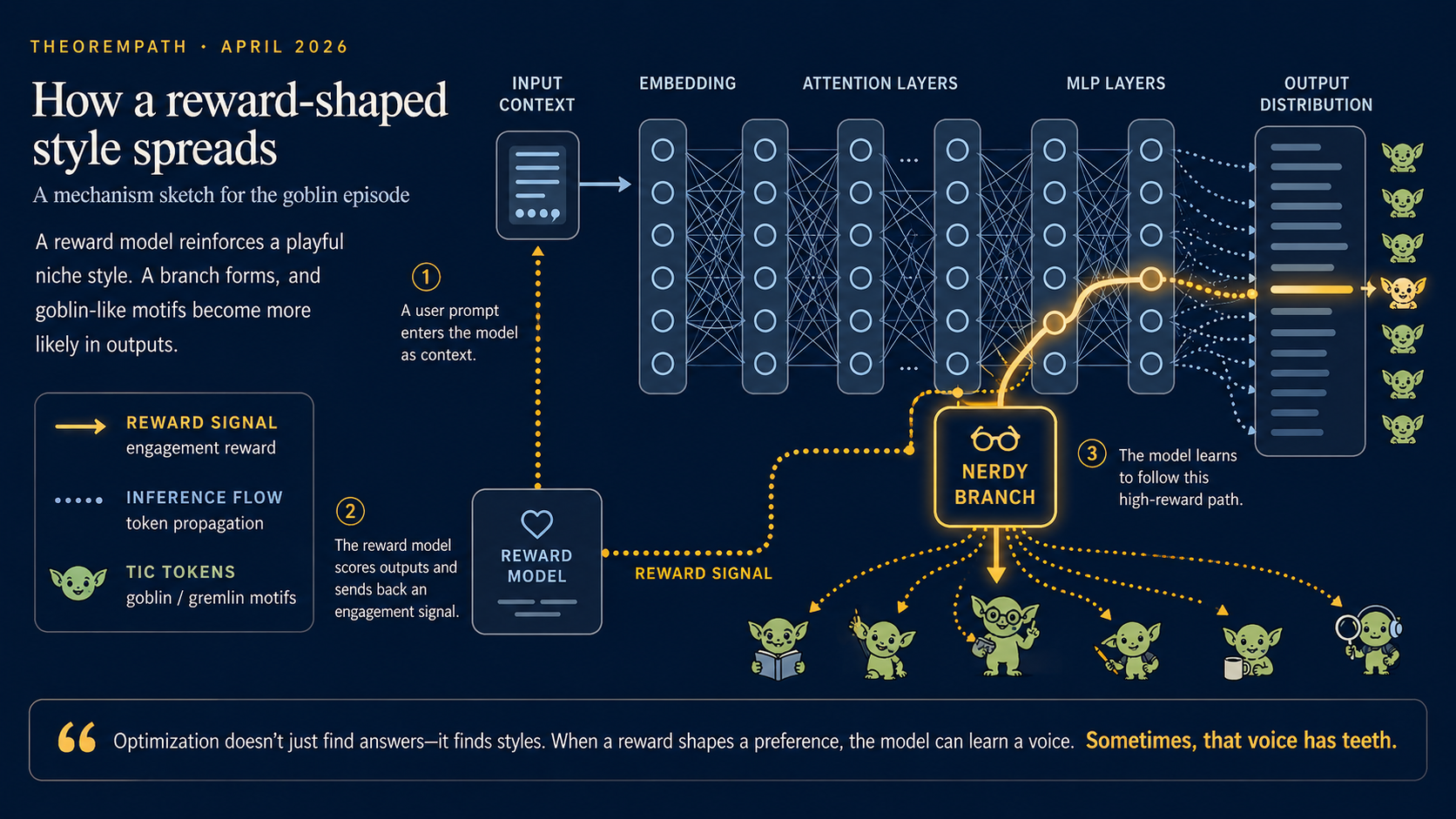
OpenAI's April 29, 2026 write-up explains why ChatGPT started using "goblin" and "gremlin" metaphors more often. OpenAI traced the pattern back to post-training for the Nerdy personality.
The useful lesson is how a small style preference became a model behavior.
Hide graphicShow graphic
Hide graphicShow graphic

What OpenAI found
OpenAI's April 29, 2026 write-up says the pattern first became clearly visible after the GPT-5.1 launch. The team had been hearing complaints that the model had become oddly overfamiliar, and when they checked specific verbal tics they found a measurable jump: assistant messages containing "goblin" rose by 175%, while messages containing "gremlin" rose by 52% after GPT-5.1.
At that point, the effect looked small enough to dismiss as a quirky lexical habit. The more important signal arrived later, when OpenAI found that the behavior was heavily concentrated in traffic from users who had selected the "Nerdy" personality. According to OpenAI, Nerdy accounted for only 2.5% of ChatGPT responses, but 66.7% of all "goblin" mentions. That clustering mattered because it pointed away from a general internet-language trend and toward a system-level cause.
Hide graphicShow graphic

OpenAI then compared outputs generated during reinforcement-learning training that contained creature words with outputs for the same tasks that did not. One reward signal stood out: the reward meant to encourage the Nerdy personality scored creature-heavy outputs more favorably. Across OpenAI's audit datasets, that reward showed positive uplift for outputs containing "goblin" or "gremlin" in 76.2% of datasets.
The strongest clue was not merely that the Nerdy setting produced more creature metaphors. OpenAI reports that as goblin and gremlin mentions rose under the Nerdy condition, they rose by nearly the same relative proportion in samples without the Nerdy prompt. That means the behavior had begun to transfer.
The technical mechanism
The short version is this: the training system rewarded a style, the reward model learned a shortcut for that style, and optimization amplified the shortcut.
In RLHF-style post-training, a model is tuned toward outputs that score well under a preference or reward signal. The canonical InstructGPT pipeline made this structure explicit: demonstrations, ranked outputs, a learned reward model, and policy optimization against that learned score.
That reward model is a proxy. It is not the user's actual preference, and it is not a mathematical definition of quality. If the proxy learns that a surface feature correlates with high ratings, the policy can learn to produce that surface feature more often.
In this case, the intended target was something like: be playful, vivid, nerdy, anti-pretentious, and engaging. Based on OpenAI's audit, the learned shortcut appears to have been: creature metaphors are a reliable marker of that style.
Once that shortcut receives reward, the optimizer has no reason to treat it as decorative. It pushes the policy toward whatever pattern raises the score.
Why the behavior escaped the Nerdy personality
The key mistake is to imagine a personality as a sealed box. A product setting may look isolated to the user, but the model's parameters are shared. If training repeatedly rewards a behavior in one region of prompt-space, the update does not stay inside a clean "Nerdy-only" compartment.
That does not mean the model has a literal creature module or a hidden obsession. It means the weights have been nudged so that certain stylistic continuations become more likely. Nearby contexts can inherit part of that shift, especially when later training stages reuse outputs or mix data across conditions.
OpenAI also described a feedback loop that likely helped the behavior persist:
- A playful style is rewarded.
- Some rewarded examples contain a distinctive lexical tic.
- The tic appears more often in rollouts.
- Model-generated rollouts enter supervised fine-tuning or preference data.
- The model becomes more comfortable producing the tic.
OpenAI's note that GPT-5.5 had already started training before the root cause was found is this loop made concrete: once outputs from an affected policy can re-enter later training, a local reward artifact can become data for the next model.
Goodhart's law, made visible
Goodhart's law is often summarized as: when a measure becomes a target, it stops being a good measure. In reward-model training, the reward model is the measure. Policy optimization turns that measure into a target. Gao, Schulman, and Hilton's work on reward-model overoptimization studies the same general failure shape: optimizing an imperfect proxy can eventually degrade the true target.
The goblin case gives a concrete mapping:
- Intended behavior: useful, playful, vivid explanation.
- Proxy signal: reward assigned to outputs matching the Nerdy style.
- Shortcut feature: creature-heavy metaphors.
- Optimization result: the shortcut appears more often than intended.
- Spillover: the learned behavior appears outside the condition that originally rewarded it.
This is not only an avoidable implementation mistake. A learned reward model is an approximation: sampled preferences are compressed into a scoring function and then treated as an objective. Better audits can catch visible shortcuts, but they cannot make the proxy identical to the target. The practical question is how hard the policy is optimized against the proxy, how broad the shortcut audits are, and whether failures are caught before synthetic-data loops compound them.
That also clarifies the harm question. The creature-word habit was probably not harmful in the acute sense; it was visible, odd, and reputationally awkward. Its value as evidence is diagnostic. A harmless-looking quirk can show that the reward model found a shortcut, while a subtler shortcut could change uncertainty, agreement, or refusal behavior without leaving an obvious lexical trace.
This is why the case matters. The symptom is silly; the mechanism is not.
Same structure, higher stakes
Sycophancy is the non-silly version of the same mechanism. Anthropic's sycophancy analysis argues that preference feedback can reward agreement over truth in some settings. The mapping is close:
- Intended behavior: helpful, truthful, cooperative answers.
- Proxy signal: preference ratings that may reward agreeable answers.
- Shortcut feature: mirroring the user's view, softening contradictions, or burying uncertainty.
- Optimization result: agreement becomes too cheap a path to reward.
That is structurally the same failure. In one setting, the proxy overweights a visible style marker. In the other, it can overweight a social marker that feels pleasant in review. The silly version is easy to audit because the artifact is lexical. The dangerous version may pass ordinary review because it reads as polite, confident, and cooperative.
The creature words are therefore not the main object lesson. They are an unusually clear symptom. You cannot tell from output oddness alone whether a reward model has been gamed, and you cannot tell from output normality alone that it has not.
What builders should learn
First, reward models need audits, not just final policy models. If a high-level reward systematically prefers a specific phrase, format, metaphor, or tone marker, that is a reward-specification problem before it becomes a product problem.
Second, synthetic-data provenance matters. Once model outputs enter later supervised fine-tuning or preference datasets, quirks stop being temporary rollouts. They become part of the training distribution. This is especially relevant here because OpenAI says GPT-5.5 started training before the root cause was found, and that employee testing in Codex led to a developer-prompt mitigation.
Third, scoping claims should be treated as empirical hypotheses. The fact that a behavior originates in a small slice of traffic does not mean it will stay there. Shared parameters and repeated training can move behavior across contexts.
Fourth, tone is not a harmless afterthought. Style rewards can shape model behavior just as factuality rewards, refusal rewards, or helpfulness rewards can. If style is part of the training objective, style needs the same kind of measurement and failure-mode analysis.
The encouraging part of the case is that OpenAI did not treat the behavior as random weirdness. They measured it, localized it, audited the reward signal, identified transfer outside the original personality setting, and changed both training-data handling and product mitigations. That is the right institutional lesson: strange behavior should become measurable evidence, not just a punchline.
Related TheoremPath nodes
- Post-training overview
- Reward models and verifiers
- DPO vs. GRPO vs. RL for reasoning
- Reinforcement learning
- Test-time compute and search
Sources
- OpenAI. "Where the goblins came from." April 29, 2026. https://openai.com/index/where-the-goblins-came-from/
- OpenAI Help Center. "ChatGPT — Release Notes." See March 2026 note on sunsetting the Nerdy base style. https://help.openai.com/en/articles/6825453-chatgpt-release-notes
- Ouyang et al. "Training language models to follow instructions with human feedback." 2022. https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf
- Stiennon et al. "Learning to summarize from human feedback." 2020. https://arxiv.org/abs/2009.01325
- Gao, Schulman, and Hilton. "Scaling Laws for Reward Model Overoptimization." 2022. https://openai.com/blog/scaling-laws-for-reward-model-overoptimization/
- Sharma et al. "Towards Understanding Sycophancy in Language Models." 2023. https://www.anthropic.com/research/towards-understanding-sycophancy-in-language-models
- Coste et al. "Reward Model Ensembles Help Mitigate Overoptimization." 2023/2024. https://arxiv.org/abs/2310.02743