Mathematical Infrastructure
Hamilton–Jacobi–Bellman Equation
The PDE characterizing the value function of a continuous-time stochastic optimal control problem. The continuous-time analog of the discrete Bellman equation, the fully nonlinear PDE that nonlinear Feynman–Kac inverts via BSDEs, and the equation Deep BSDE solves numerically in high dimensions.
Prerequisites
Learning position
Read this page in the graph.
mathematical-infrastructure | layer 3 | tier 2. This page has 2 direct prerequisites and 1 published dependent.
What next
Backward Stochastic Differential EquationsThis is the first curated or graph-derived continuation from the current page.
Evidence badge
Claim statusThis page has no public Lean mapping yet. Use the evidence page to inspect how claim status labels work.
Why This Matters
Hide overviewShow overview
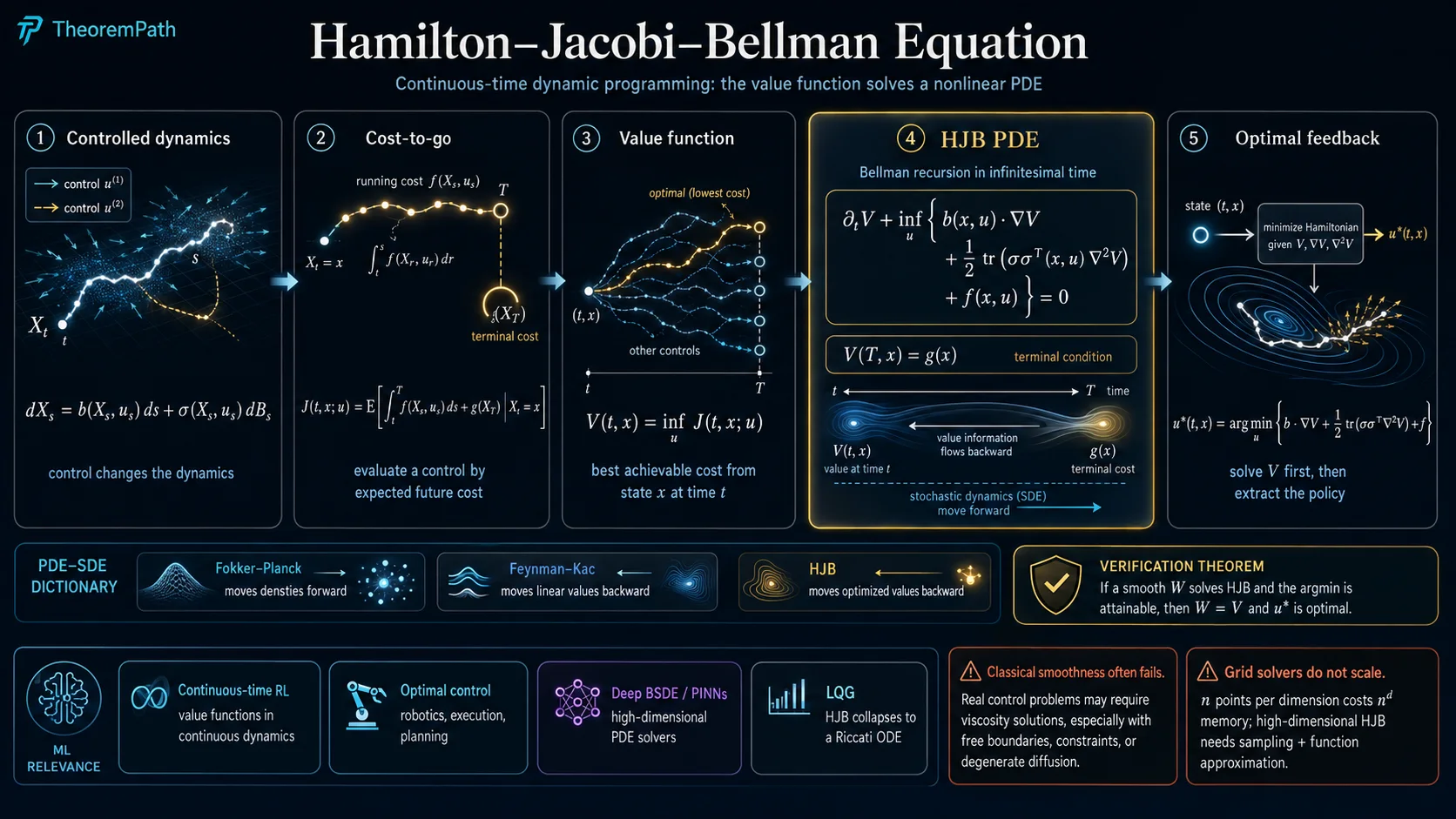
The Hamilton–Jacobi–Bellman equation is the continuous-time Bellman equation: the PDE that the value function of a stochastic control problem must satisfy. The discrete Bellman recursion becomes, after a Taylor expansion of the expectation in the time step, a nonlinear second-order PDE in . Every result that holds for the discrete dynamic-programming equation — optimal substructure, the policy read off from the Bellman operator, the contraction-mapping convergence of value iteration — has a continuous-time analog phrased in HJB language.
HJB is also the canonical fully nonlinear parabolic PDE that arises from probability. The nonlinearity sits inside an infimum (or supremum) over the control variable, and that infimum is exactly the Hamiltonian of the problem. The Feynman–Kac formula handles the linear case (no control, drift fixed); the BSDE machinery of Pardoux and Peng (1992) extends to semilinear PDEs; HJB sits at the top of this hierarchy as the fully nonlinear PDE that BSDEs with a control-dependent driver solve in the most general setting.
In modern ML, HJB is the equation that continuous-time reinforcement learning, optimal stopping, optimal execution in finance, and robotic control problems all reduce to. The grid-based curse of dimensionality makes classical HJB solvers useless above , which is the entire reason the Deep BSDE method and DGM / PINN-style PDE solvers exist: to approximate in regimes where finite differences cannot.
A useful slogan: Fokker–Planck moves densities forward, Feynman–Kac moves linear value functions backward, HJB moves optimized value functions backward. The three together cover the standard PDE-SDE dictionary for stochastic control.
Mental Model
The principle of optimality says: an optimal trajectory from is also optimal on every sub-interval for , given the state reached at time . Apply this principle infinitesimally. For a small time step , the optimal cost from equals the running cost incurred over plus the value at , minimized over the control choice on that interval. Taylor-expand both sides in , take the limit , and the result is a PDE: the infimum over controls of (running cost plus generator of ) equals . That PDE is HJB.
The supremum (or infimum) over controls in HJB is the dynamic-programming analog of the in the discrete Bellman operator. Reading off the control that achieves the infimum gives the optimal feedback policy .
Formal Statement
Hamilton–Jacobi–Bellman Equation
Fix a horizon and an admissible control set . Consider the controlled SDE on with , where is a progressively measurable control process. The cost functional is
with running cost and terminal cost . The value function is , where the infimum is over admissible controls.
Under regularity, satisfies the HJB equation
with terminal condition . The bracketed expression is the Hamiltonian evaluated at , . Maximization (rather than minimization) gives the same PDE with replacing , used in reward-maximizing formulations.
The equation is fully nonlinear: the infimum over couples drift, diffusion, and running cost in a way that is not affine in or . This is what distinguishes HJB from the linear backward Kolmogorov equation that Feynman–Kac inverts.
The Verification Theorem
The HJB equation is necessary for the value function under regularity. The verification theorem is the converse: a smooth solution of HJB whose infimum is attained by a measurable feedback control is the value function, and is optimal. This is the workhorse result that turns "find satisfying a PDE" into "you have just solved the control problem."
HJB Verification Theorem
Statement
Under the assumptions above, for all , and the feedback control , where solves the closed-loop SDE with , is optimal: .
Intuition
Apply Itô's formula to along an arbitrary admissible control on . The drift of is , which the HJB inequality bounds below by for every choice of . Integrating gives , so . For the optimal feedback , the HJB equation holds with equality and the bound becomes tight, giving .
Proof Sketch
For arbitrary admissible , apply Itô to on :
The HJB equation gives pointwise (since the infimum over is the smallest value), with equality at . Take expectations; the stochastic integral is a martingale (polynomial growth plus BDG), so
which rearranges to . Equality holds along , so and achieves the infimum.
Why It Matters
This is the bridge between PDE analysis and control. Solve the HJB PDE analytically or numerically; read the optimal feedback off the argmin in the Hamiltonian; the resulting closed-loop SDE is guaranteed optimal among all admissible controls. Without verification, the HJB equation would just be a necessary condition and you would still need a separate optimality proof; with verification, the PDE is the optimality certificate. (the value function), and is an optimal control.
Failure Mode
The smoothness assumption fails for many problems of practical interest: optimal stopping (where has a free boundary and jumps), singular control, problems with state constraints, and degenerate diffusions where is rank-deficient. In all these cases the classical verification theorem does not apply directly, and one needs viscosity solutions or a regularization argument. A second failure mode: the infimum may not be attained inside (e.g., if is open or unbounded), in which case the candidate feedback is undefined and the closed-loop SDE has no strong solution.
Viscosity Solutions
For most realistic stochastic control problems the value function is not and the classical verification theorem does not apply. The right notion of "solution" is the viscosity solution of Crandall and Lions (1983), extended to second-order PDEs by Crandall, Ishii, and Lions (1992).
The idea: replace pointwise differentiation of with a test-function inequality. is a viscosity sub-solution if and only if, for every smooth test function with attaining a local maximum at , the HJB operator applied to is non-positive at . Super-solution is the dual inequality. A viscosity solution is both. This sidesteps the need for to be twice differentiable: the test function carries the derivatives, and the inequality only constrains at points where smooth functions can "touch" it.
Two facts make this framework load-bearing for HJB. First, under mild assumptions (continuity of , polynomial growth) the value function is the unique continuous viscosity solution of HJB. Second, viscosity solutions are stable under uniform convergence, so numerical schemes that approximate the operator (monotone finite differences, semi-Lagrangian methods, BSDE schemes) converge to the viscosity solution under Barles–Souganidis-style consistency conditions. Ishii's lemma is the key technical tool for the comparison principle that gives uniqueness.
Connection to Feynman–Kac and BSDEs
Strip the control out of HJB. With and fixed and the infimum dropped, the equation becomes the linear backward PDE
which is exactly what the Feynman–Kac formula inverts: . So the linear, no-control HJB is Feynman–Kac. The expectation representation is the value function of the trivial control problem with no decisions to make.
Restore the control, and the running cost becomes nonlinear in through the infimum. The exact correspondence depends on whether the control enters the diffusion, and this distinction is essential.
Semilinear case (control affects drift only). When the diffusion does not depend on , the HJB PDE is semilinear: it is nonlinear in but the second-order term is fixed and linear in . The nonlinear Feynman–Kac formula of Pardoux and Peng (1992) gives the representation where solve a standard backward SDE
with driver . The BSDE pair encodes both and along sample paths of . This is the regime in which classical BSDE theory and the Deep BSDE method operate, and it covers a large class of stochastic-control problems (LQG with control-independent noise, Merton portfolio, optimal execution with fixed liquidity) but not every HJB equation.
Fully nonlinear case (control enters the diffusion). When depends on , the infimum couples and nonlinearly through both the drift and the diffusion term, and HJB becomes fully nonlinear. Standard BSDEs of Pardoux–Peng type are not sufficient: the natural stochastic representation is the second-order BSDE (2BSDE) framework of Cheridito, Soner, Touzi, and Victoir (2007) and Soner, Touzi, and Zhang (2012), which adds a process encoding and is formulated under a non-dominated family of measures. Equivalently, fully nonlinear HJB is handled at the PDE level via viscosity solutions (Crandall, Ishii, Lions 1992). The Deep BSDE method extends to this regime via deep 2BSDE schemes (Beck, E, Jentzen 2019), but the vanilla BSDE story quoted above is the semilinear special case. Reading "BSDEs solve HJB" without the semilinear / fully nonlinear caveat is one of the most common slips in this area.
Worked Example: Linear-Quadratic-Gaussian Control
Take linear dynamics, quadratic cost, additive Gaussian noise:
with symmetric positive semidefinite, symmetric positive definite, and a constant matrix (control-independent diffusion). Guess the value function is quadratic in : for some matrix and scalar to be determined.
Compute and . Substitute into HJB:
The infimum is unconstrained quadratic in ; setting the gradient to zero gives , a linear feedback of the state. Plug back in:
Symmetrizing and matching the and constant terms separately gives the matrix Riccati ODE
and , . The Riccati equation is what the HJB PDE collapses to under the LQG ansatz: a finite-dimensional ODE in the matrix , solvable by standard ODE integrators in any dimension where you can store .
Two consequences worth flagging. First, the optimal control is linear in the state with gain — this is the classical LQR result, and it is the reason LQG / iLQR / DDP underlie so much of model-based RL and trajectory optimization. Second, the noise enters only through the additive scalar and not through : the optimal feedback is certainty-equivalent — solve the deterministic problem, ignore the noise, and you get the same controller. Certainty equivalence is special to LQG and breaks immediately when , , or the dynamics depend on multiplicatively or when costs are not quadratic.
Common Confusions
HJB is for the value function, not the optimal policy directly
The equation solves for . The optimal feedback is read off as the argmin (or argmax) inside the Hamiltonian: . You cannot solve for without first having (or a parametric guess for , as in the LQG example), which is why "policy iteration in continuous time" alternates between solving a linear PDE for given and updating from the argmin. The HJB equation itself is the fixed point of this alternation.
HJB runs backward in time; Fokker–Planck runs forward
HJB has a terminal condition and is solved backward from to . Its dual, Fokker–Planck, has an initial condition and is solved forward from to . They use the generator and its adjoint respectively. Confusing the time direction is a common implementation bug: the Euler-step update for HJB has the opposite sign on the time derivative compared to forward parabolic solvers.
Classical HJB grid solvers blow up exponentially in dimension
A finite-difference grid for with points per axis costs memory; for this is hopeless. This is the entire motivation for Deep BSDE, DGM, PINNs in control, and policy-gradient methods in continuous-time RL: they sidestep the grid by sampling trajectories (Monte Carlo, polynomial in ) and parameterizing or with neural networks. The trade-off is approximation error in versus exponential blow-up in storage; for the trade-off favors approximation every time.
Exercises
Problem
Specialize the LQG worked example to the scalar case: with running cost and terminal cost , all coefficients positive scalars. Derive the scalar Riccati ODE for and the optimal feedback from HJB by direct substitution.
Problem
Show that the HJB equation reduces to the linear backward PDE that Feynman–Kac inverts when there is no control: take a single point, drift , diffusion , running cost , and verify that the Feynman–Kac representation recovers exactly the value function defined by the cost integral.
References
- Bellman, Dynamic Programming (Princeton University Press, 1957). The original source for the principle of optimality and the discrete Bellman equation that HJB continuous-time-extends.
- Fleming and Rishel, Deterministic and Stochastic Optimal Control (Springer, 1975). The foundational rigorous treatment; Chapters 5–6 cover the stochastic HJB equation and the verification theorem under classical smoothness.
- Fleming and Soner, Controlled Markov Processes and Viscosity Solutions (2nd ed., Springer, 2006), Chapters 4–5. The standard modern reference for HJB with full viscosity-solution machinery, including comparison principles and Ishii's lemma.
- Yong and Zhou, Stochastic Controls: Hamiltonian Systems and HJB Equations (Springer, 1999), Chapters 4–5. Self-contained derivation of HJB from dynamic programming, verification theorem, and connections to the stochastic maximum principle.
- Pham, Continuous-time Stochastic Control and Optimization with Financial Applications (Springer, 2009). Finance-flavored treatment with worked LQG, Merton portfolio, and optimal stopping via HJB variational inequalities.
- Crandall and Lions, Viscosity solutions of Hamilton–Jacobi equations (Transactions of the AMS 277, 1983). The original viscosity-solution paper for first-order HJ; the extension to second-order HJB is in Crandall, Ishii, and Lions, "User's guide to viscosity solutions" (Bulletin of the AMS 27, 1992).
- Pardoux and Peng, Backward stochastic differential equations and quasilinear parabolic partial differential equations (Lecture Notes in Control and Information Sciences 176, 1992). The nonlinear Feynman–Kac formula that connects BSDEs to semilinear PDEs and underlies the BSDE route to HJB.
- Han, Jentzen, and E, Solving high-dimensional partial differential equations using deep learning (PNAS 115, 2018). The Deep BSDE method, demonstrated on HJB and Allen–Cahn problems where grid solvers fail.
Next Topics
- Deep BSDE Method: neural-network solver for high-dimensional HJB via the BSDE reformulation.
- Backward SDE Theory: the Pardoux–Peng nonlinear Feynman–Kac formula that bridges BSDEs and semilinear PDEs.
- Feynman–Kac Formula: the linear special case of HJB, recovered when there is no control.
- Stochastic Differential Equations: the controlled diffusion that underlies the cost functional.
- Fokker–Planck Equation: the forward / density-side dual of the backward HJB equation.
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
2- Feynman–Kac Formulalayer 3 · tier 2
- Stochastic Differential Equationslayer 3 · tier 2
Derived topics
1- Backward Stochastic Differential Equationslayer 3 · tier 2
Graph-backed continuations