Sampling MCMC
Langevin Dynamics
The overdamped Langevin SDE: gradient descent plus calibrated Gaussian noise. The mathematical object behind SGLD, ULA, and energy-based MCMC samplers, and the simplest sampler with provable polynomial-time convergence on log-concave targets.
Prerequisites
Learning position
Read this page in the graph.
sampling-mcmc | layer 3 | tier 2. This page has 7 direct prerequisites and 2 published dependents.
What next
Score MatchingThis is the first curated or graph-derived continuation from the current page.
Evidence badge
Claim statusThis page has no public Lean mapping yet. Use the evidence page to inspect how claim status labels work.
Why This Matters
Hide overviewShow overview
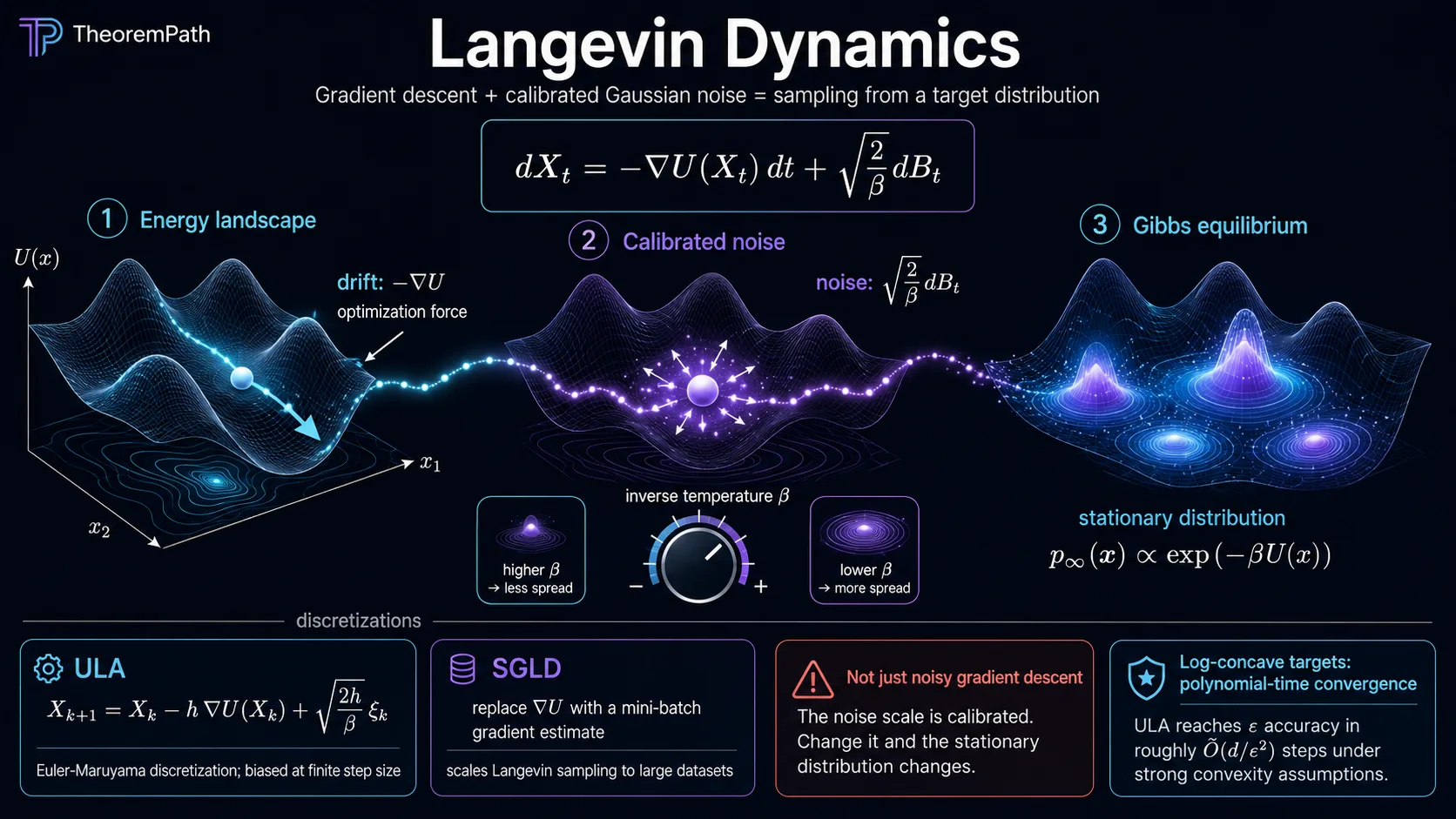
If you want to sample from a target distribution and you can compute , you have a clean recipe: run the SDE
and at large the law of converges to . This is overdamped Langevin dynamics. It is gradient descent on plus a precisely calibrated Gaussian noise, and the calibration is what makes the distribution — not just the trajectory — converge to the right place.
Almost every gradient-based MCMC sampler in modern ML is a discretization or perturbation of this SDE. The unadjusted Langevin algorithm (ULA) is the Euler-Maruyama discretization. SGLD (Welling-Teh 2011) replaces with a stochastic mini-batch estimate. Score-based diffusion models generate samples by running a Langevin-like reverse SDE whose drift is the learned score . MALA, HMC, and proximal Langevin are all targeted refinements of the same machinery.
Langevin dynamics is also the SDE that gives the cleanest non-asymptotic guarantees in modern sampling theory. Dalalyan (2017) and Durmus-Moulines (2017) showed that ULA on a strongly-log-concave target reaches a prescribed total-variation distance from in steps, polynomial in dimension with no intractable constants. This is the kind of guarantee Metropolis-Hastings methods cannot provide and that explains why Langevin-based methods are the default for sampling from energy-based models in dimensions above ~50.
Mental Model
Read the dynamics as a competition between two forces. The drift pulls the particle downhill toward modes of , exactly like gradient descent. The noise pushes the particle around with a magnitude that scales with the inverse temperature . At temperature (no noise) you recover deterministic gradient flow, which gets stuck at the nearest local minimum. At temperature (only noise) you get pure Brownian motion, which never localizes anywhere. The Gibbs measure is the unique stationary balance: probability concentrates near minima of but spreads out according to the temperature, and the relative weights between minima depend on times the energy gap.
The key calibration is the factor in front of : any other coefficient gives a different stationary distribution. This is not a tunable hyperparameter; it is set by the requirement that the Fokker-Planck equation have as its stationary density.
Formal Definition
Overdamped Langevin SDE
For a potential with integrable and a standard -dimensional Brownian motion , the overdamped Langevin SDE at inverse temperature is
The associated Fokker-Planck equation is , which can be rewritten in gradient-flow form where . This is the formal sense in which Langevin dynamics is the gradient flow of relative entropy in the Wasserstein-2 metric (Jordan, Kinderlehrer, and Otto, 1998).
The "overdamped" qualifier distinguishes this from the second-order underdamped Langevin SDE that includes a momentum variable and is the basis of Hamiltonian Monte Carlo.
Stationary Distribution
Gibbs Measure is the Stationary Distribution of Langevin
Statement
Under the assumptions above, with is the unique invariant density of the Langevin Fokker-Planck operator . The dynamics is reversible with respect to , and detailed balance holds: the equilibrium probability current is identically zero.
Intuition
Plug into and watch the cancellation. The drift term . The diffusion term . They sum to zero. The factor in the SDE is exactly what makes this cancellation work.
Proof Sketch
For uniqueness, restrict to . The Fokker-Planck operator, when symmetrized as , is self-adjoint and negative semidefinite with a simple eigenvalue when has connected sublevel sets. The eigenvector for is . Standard semigroup theory then gives in for any initial with finite relative entropy.
Why It Matters
This is the entire reason Langevin dynamics works as a sampler: with the right calibration, the SDE has the target distribution as its unique equilibrium. Tampering with the noise scale (e.g., using instead of ) changes the stationary distribution to , the same modes but a sharper temperature. Methods that "anneal " (simulated annealing) exploit this dependence to escape local minima at high temperature, then localize at low temperature. The Gibbs measure is the unique stationary distribution of the overdamped Langevin SDE.
Failure Mode
The result requires to be integrable. For (linear potential) this fails: the dynamics drifts to infinity and has no stationary distribution. Same for with super-quadratic decay at infinity in some directions. Practical samplers handle this with confinement: add a quadratic regularizer to if the target is not provably tight.
Convergence Rate: Log-Sobolev and Bakry-Emery
The asymptotic statement " converges to " is qualitative. The quantitative statement requires a functional inequality for the stationary measure. The cleanest one is the log-Sobolev inequality (LSI) . Whenever satisfies LSI with constant , the law of converges to in KL divergence at exponential rate :
Bakry-Emery's curvature criterion says: if for some (i.e., the rescaled potential is strongly convex), then satisfies LSI with constant at least , and the convergence rate is at least . This is the sharpest and cleanest convergence theorem for Langevin dynamics on log-concave targets.
For non-log-concave (multimodal energy landscapes), LSI can fail catastrophically. Holley-Stroock perturbation gives an LSI constant that scales like where is the energy barrier between modes, producing exponential slowdown in the barrier height. This is the mathematical statement of "Langevin gets stuck at low temperature."
Numerical Discretization: ULA
The Unadjusted Langevin Algorithm is Euler-Maruyama applied to the Langevin SDE:
ULA does not exactly preserve the Gibbs measure. The discretization introduces a bias of size in total variation. There is a clean non-asymptotic theory.
Dalalyan's Non-Asymptotic ULA Bound
Statement
Under the assumptions above, the law of satisfies provided for an absolute constant and step size tuned proportionally to .
Intuition
The proof couples the continuous-time Langevin SDE (which converges exponentially fast by Bakry-Emery) with its Euler-Maruyama discretization. The discretization bias accumulates linearly in the number of steps but is per step, so total bias is . Choosing small enough balances continuous-time convergence error against discretization bias.
Proof Sketch
Let be the law of the continuous Langevin SDE at time . Triangle inequality: . The first term is the discretization bias bounded via Girsanov's theorem and the Lipschitz hypothesis on ; it scales as (Dalalyan 2017, Theorem 1). The second term decays as by Bakry-Emery. Optimize over the sum.
Why It Matters
This was the first dimension-polynomial sampling result for a gradient-based MCMC method on log-concave targets. Earlier methods (MH, HMC) only had asymptotic guarantees with constants that were either intractable or known to scale exponentially in . The result lit a research program: faster Langevin variants (MALA: gradient queries; underdamped Langevin: ; proximal Langevin for non-smooth ), all measured against this baseline. After steps, the ULA iterate is within total-variation distance of the Gibbs measure.
Failure Mode
The result requires strong log-concavity (positive lower bound on the Hessian). Weakly log-concave or multimodal targets fall outside the hypothesis, and ULA's bias does not vanish in the standard sense. For non-log-concave problems, the Metropolis adjustment (MALA) is needed to remove the bias, but MALA's mixing time can be exponentially worse in the energy-barrier height.
Stochastic-Gradient Variant: SGLD
Welling and Teh (2011) introduced Stochastic Gradient Langevin Dynamics (SGLD): replace the exact gradient in ULA with a mini-batch estimate from a random subset of data, and decay the step size so that the discretization bias and gradient-noise bias both vanish in the limit:
The intuition: at large , the injected Gaussian noise dominates the mini-batch noise (because ), and the algorithm transitions from SGD-like exploration to Langevin-like sampling. Without the decay, the mini-batch noise dominates indefinitely and the stationary distribution is not the Gibbs measure but a perturbation depending on the gradient covariance, a phenomenon that motivates the entire SGD-as-SDE literature.
Common Confusions
Langevin dynamics is not gradient flow
Gradient flow converges to the minimizer of ; Langevin dynamics converges to the Gibbs distribution . These give different answers when is multimodal, when is finite, or when you care about uncertainty rather than a point estimate. The noise term is not "regularization" or "exploration heuristic" — it is what makes Langevin a sampler instead of an optimizer, and removing it loses the entire Bayesian / sampling story.
The step size of ULA controls bias, not variance
Standard SGD intuition: small step sizes give low variance and slow convergence, large step sizes give the opposite. For ULA the trade-off is qualitatively different: small step sizes give low bias against the true Gibbs measure but slow continuous-time mixing; large step sizes give high bias (the iterates' stationary distribution is a perturbation of Gibbs). Throwing CPU at smaller and smaller is the right move when bias is the bottleneck; there is no diminishing return on step-size shrinkage that mirrors the variance / step-size trade-off in optimization.
Underdamped Langevin is a different SDE, not just a numerical trick
Overdamped Langevin lives in state space . Underdamped Langevin lives in phase space with a momentum variable and friction coefficient : , . The stationary distribution is , which marginalizes back to Gibbs in . The mixing time scales as instead of because momentum gives the dynamics inertia to traverse low-curvature regions faster. This is the SDE behind HMC.
Exercises
Problem
For the Gaussian target on , write out the Langevin SDE explicitly, solve it in closed form starting from , and compute the variance of . Confirm that as , matching the Gibbs marginal.
Problem
Consider a "double-well" potential on . Show that the LSI constant of the Gibbs measure degrades exponentially in as , and explain what this implies for the mixing time of Langevin dynamics on this target.
References
Canonical:
- Pavliotis, Stochastic Processes and Applications (Springer, 2014), Chapter 4. Cleanest modern treatment, including ergodicity, spectral gap, and exit-time theory for Langevin.
- Bakry, Gentil, and Ledoux, Analysis and Geometry of Markov Diffusion Operators (Springer Grundlehren, 2014). The authoritative reference on log-Sobolev, Bakry-Emery curvature, and exponential ergodicity for diffusion semigroups.
- Pavliotis and Stuart, Multiscale Methods: Averaging and Homogenization (Springer, 2008), Chapter 6. Connects Langevin dynamics to its overdamped limit from underdamped Langevin via singular perturbation.
- Roberts and Tweedie, Exponential convergence of Langevin distributions and their discrete approximations (Bernoulli 2, 1996). The classical reference for Langevin ergodicity in TV distance.
Current:
- Dalalyan, Theoretical guarantees for approximate sampling from smooth and log-concave densities (Journal of the Royal Statistical Society B, 2017). The non-asymptotic ULA convergence theorem cited above.
- Durmus and Moulines, Nonasymptotic convergence analysis for the unadjusted Langevin algorithm (Annals of Applied Probability 27, 2017). The companion / parallel non-asymptotic analysis with sharper constants for some regimes.
- Welling and Teh, Bayesian learning via stochastic gradient Langevin dynamics (ICML 2011). The original SGLD paper; introduced gradient-noise + decreasing step sizes for posterior sampling at scale.
- Cheng, Chatterji, Bartlett, and Jordan, Underdamped Langevin MCMC: A non-asymptotic analysis (COLT 2018). Shows underdamped Langevin achieves mixing-time scaling, beating ULA's .
Next Topics
- Score Matching: training a network on , the same vector field that drives Langevin dynamics when .
- SGD as SDE: SGD viewed as a Langevin-like SDE where the gradient noise plays the role of .
- Diffusion Models: generative models that sample by running a reverse Langevin-style SDE with learned drift.
- Time Reversal of SDEs: the SDE-reversal result that turns forward Langevin noising into a backward sampler.
- Stochastic Differential Equations: the parent framework Langevin specializes.
Last reviewed: April 18, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
7- Score Matchinglayer 3 · tier 1
- Stochastic Processes for MLlayer 2 · tier 2
- Fokker–Planck Equationlayer 3 · tier 2
- Hamiltonian Monte Carlolayer 3 · tier 2
- SGD as a Stochastic Differential Equationlayer 3 · tier 2
Derived topics
2- Singular Learning Theorylayer 3 · tier 1
- Diffusion Modelslayer 4 · tier 1
Graph-backed continuations