ML Methods
Perceptron
Rosenblatt's perceptron (1958): the simplest neural network, the first learning algorithm with a convergence proof, and the lesson that linear separability is both powerful and limiting.
Learning position
Read this page in the graph.
ml-methods | layer 1 | tier 2. This page has 0 direct prerequisites and 3 published dependents.
What next
Support Vector MachinesThis is the first curated or graph-derived continuation from the current page.
Evidence badge
Claim statusThis page has no public Lean mapping yet. Use the evidence page to inspect how claim status labels work.
Why This Matters
Hide overviewShow overview
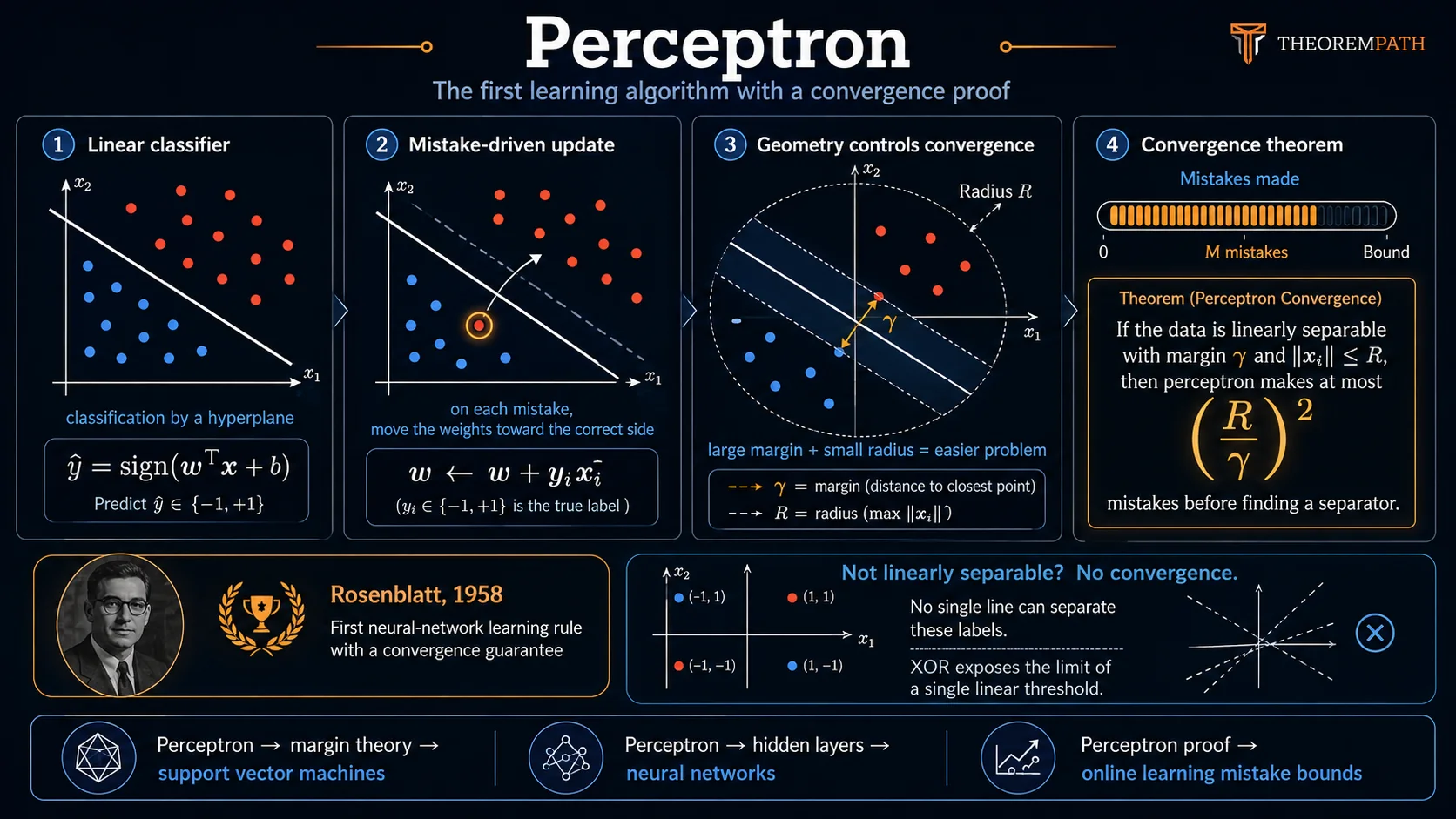
The perceptron is the ancestor of all neural networks. Frank Rosenblatt introduced it in 1958, and it came with something remarkable: a proof that the learning algorithm converges to a correct classifier whenever one exists.
This was the first convergence guarantee for a learning algorithm. The perceptron convergence theorem shows that if the data is linearly separable, the algorithm finds a separating hyperplane in a bounded number of steps. The bound depends only on the geometry of the data (the margin and radius), not on the dimension.
Understanding the perceptron also teaches you what linearity cannot do. The XOR problem, which the perceptron cannot solve, was the catalyst for the "AI winter" and eventually motivated multi-layer networks and backpropagation.
Mental Model
Picture points in colored red and blue. The perceptron tries to find a hyperplane that separates the two colors. It starts with an arbitrary hyperplane, then adjusts it each time it makes a mistake: nudge the hyperplane toward the misclassified point. If a perfect separating hyperplane exists, this process terminates.
Formal Setup and Notation
We have training data where and .
Perceptron Decision Rule
Given a weight vector and bias , the perceptron classifies input as:
The decision boundary is the hyperplane .
For notational convenience, we absorb the bias into the weight vector by appending a 1 to each input: , . The decision rule becomes .
Perceptron Learning Rule
Initialize . At each step , pick a training example . If it is misclassified (), update:
If correctly classified, do nothing: .
The update is intuitive: if and the point is misclassified, we are predicting negative, so we add to to push the prediction more positive at . If , we subtract .
Core Definitions
Linear Separability with Margin
A dataset is linearly separable with margin if there exists a unit vector () such that:
The margin is the minimum distance from any point to the separating hyperplane (after projecting onto ).
Radius of the Data
The radius of the dataset is:
This is the radius of the smallest ball centered at the origin containing all data points.
Main Theorems
Perceptron Convergence Theorem
Statement
If the data is linearly separable with margin and all points have , then the perceptron algorithm makes at most:
mistakes before converging to a linear separator.
Intuition
The bound is purely geometric. The ratio measures how "easy" the classification problem is: large margin and small radius means few mistakes. The bound does not depend on the dimension or the number of training points . This is remarkable: the perceptron can work in very high dimensions as long as the margin is large relative to the data spread.
Proof Sketch
Track two quantities across the mistakes made by the algorithm:
Lower bound on : At each mistake, (because each update adds at least to the projection onto ). Since , we get .
Upper bound on : At each mistake, (the middle term is non-positive because the point was misclassified). So .
Combining: , so .
Why It Matters
This is one of the earliest and cleanest convergence proofs in machine learning. The potential function argument (tracking both a lower and upper bound on the weight vector) is a proof technique that appears throughout online learning theory. The bound also foreshadows the importance of margin in SVMs.
Failure Mode
If the data is not linearly separable, the perceptron never converges. It cycles through the data making mistakes forever. There is no approximate guarantee. This is the fundamental limitation that motivates soft-margin SVMs and neural networks.
Proof Ideas and Templates Used
The perceptron convergence proof uses a potential function argument: define a quantity (here ) that is bounded from above and below by different functions of the number of mistakes. Squeezing these together gives the bound.
This is the same template used in many online learning proofs, including the analysis of the Winnow algorithm and online mirror descent.
Canonical Examples
Perceptron on 2D data
Consider four points: with label , with label , with label , with label . These are linearly separable. The perceptron starts at , encounters and misclassifies it (predicts 0), updates to . The next point is correctly classified (, predict ). After a few passes, the algorithm converges.
Extensions
The basic perceptron handles only linearly separable data and produces an arbitrary separator. Three extensions are standard.
Voted and Averaged Perceptron
Freund and Schapire (1999) addressed the non-separable case. The voted perceptron stores every weight vector produced during training together with its "survival count" (the number of consecutive examples it classifies correctly before the next mistake). At test time the prediction is a weighted majority vote of the stored classifiers.
The averaged perceptron approximates the voted version with a single weight vector , computed incrementally without storing the history. It matches voted-perceptron test accuracy in practice at a fraction of the cost. Freund and Schapire proved a PAC-style generalization bound for the voted perceptron of the form , mirroring the mistake bound. Collins (2002) popularized the averaged perceptron for structured prediction in NLP, where it remained a competitive baseline well into the deep-learning era.
Kernel Perceptron
Aizerman, Braverman, and Rozonoer (1964) gave the dual formulation. Track the multiset of mistake examples ; the weight vector is implicit: . Inner products with become , which can be replaced by a kernel . The convergence theorem still applies (the bound holds in the feature space induced by ), and the algorithm now classifies data that is linearly separable only after a nonlinear transformation. This is the kernel-trick precursor to support vector machines.
Multi-Class Perceptron
Crammer and Singer (2003) generalized the update to multi-class outputs by maintaining one weight vector per class and updating both the weight for the true class and the weight for the highest-scoring wrong class on each mistake.
Connection to Online Learning
The mistake bound is itself a regret bound: it guarantees that the cumulative number of errors of the online learner is bounded by a quantity that depends only on the geometry of the data and the best fixed classifier in hindsight. The same potential-function template that proves the perceptron bound generalizes to online mirror descent and online gradient descent. The same ratio also appears in margin-based PAC generalization bounds for linear classifiers (Bartlett 1998, Schölkopf-Smola 2002), making the perceptron analysis a direct ancestor of margin theory.
Common Confusions
The perceptron finds a separator, not the best separator
The perceptron finds some separating hyperplane, not the maximum-margin one. The specific hyperplane depends on the order in which points are processed and the initialization. Finding the maximum-margin hyperplane is the job of support vector machines.
The XOR problem is about representational capacity, not the algorithm
The perceptron cannot solve XOR because no single hyperplane can separate the four XOR points. This is a limitation of the linear model, not of the learning algorithm. Adding a hidden layer (multi-layer perceptron) solves XOR, but the perceptron convergence theorem no longer applies to the training of multi-layer networks.
Summary
- Decision rule:
- Update on mistake:
- Convergence bound: at most mistakes if data is linearly separable with margin
- The bound depends on geometry (margin and radius), not dimension
- Does not converge if data is not linearly separable
- Historically: the first learning algorithm with a convergence proof (1958)
Exercises
Problem
The perceptron is run on a dataset where and the margin is . What is the maximum number of mistakes the algorithm can make?
Problem
Show that the XOR function (inputs with labels ) is not linearly separable. Why does this kill the perceptron?
Problem
Prove that the perceptron convergence bound is tight: construct a dataset in where the perceptron makes exactly mistakes.
References
Canonical:
- Rosenblatt, "The perceptron: a probabilistic model for information storage and organization in the brain" (1958)
- Novikoff, "On convergence proofs for perceptrons" (1962)
- Block, "The perceptron: a model for brain functioning. I" (1962): contemporary independent convergence proof
Extensions:
- Aizerman, Braverman & Rozonoer, "Theoretical foundations of the potential function method in pattern recognition learning" (1964) — kernel perceptron / dual form
- Freund & Schapire, "Large margin classification using the perceptron algorithm" (Machine Learning 1999) — voted and averaged perceptron with PAC bounds
- Collins, "Discriminative training methods for hidden Markov models: theory and experiments with perceptron algorithms" (EMNLP 2002) — averaged perceptron for structured prediction
- Crammer & Singer, "Ultraconservative online algorithms for multiclass problems" (JMLR 2003) — multi-class perceptron
Current:
- Shalev-Shwartz & Ben-David, Understanding Machine Learning (2014), Chapter 9
- Mohri, Rostamizadeh, Talwalkar, Foundations of Machine Learning (2018), Chapter 8
- Hastie, Tibshirani, Friedman, The Elements of Statistical Learning (2009), Chapter 4.5
Next Topics
The natural next steps from the perceptron:
- Support vector machines: finding the maximum-margin separator
- Feedforward networks and backpropagation: overcoming the linear separability limitation
Last reviewed: April 26, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
0No direct prerequisites are declared; this is treated as an entry point.
Derived topics
3- Feedforward Networks and Backpropagationlayer 2 · tier 1
- Support Vector Machineslayer 2 · tier 1
- Hebbian Learninglayer 4 · tier 3
Graph-backed continuations