LLM Construction
Synthetic Data Distillation
Data-centric distillation: instead of matching teacher logits, train the student on a carefully synthesized corpus written by a stronger teacher. Phi and Orca style pipelines, explanation tuning, filtering, and why the corpus is the model.
Prerequisites
Learning position
Read this page in the graph.
llm-construction | layer 3 | tier 2. This page has 2 direct prerequisites and 2 published dependents.
What next
Reasoning Data CurationThis is the first curated or graph-derived continuation from the current page.
Evidence badge
Claim statusThis page has no public Lean mapping yet. Use the evidence page to inspect how claim status labels work.
Why This Matters
Hide overviewShow overview
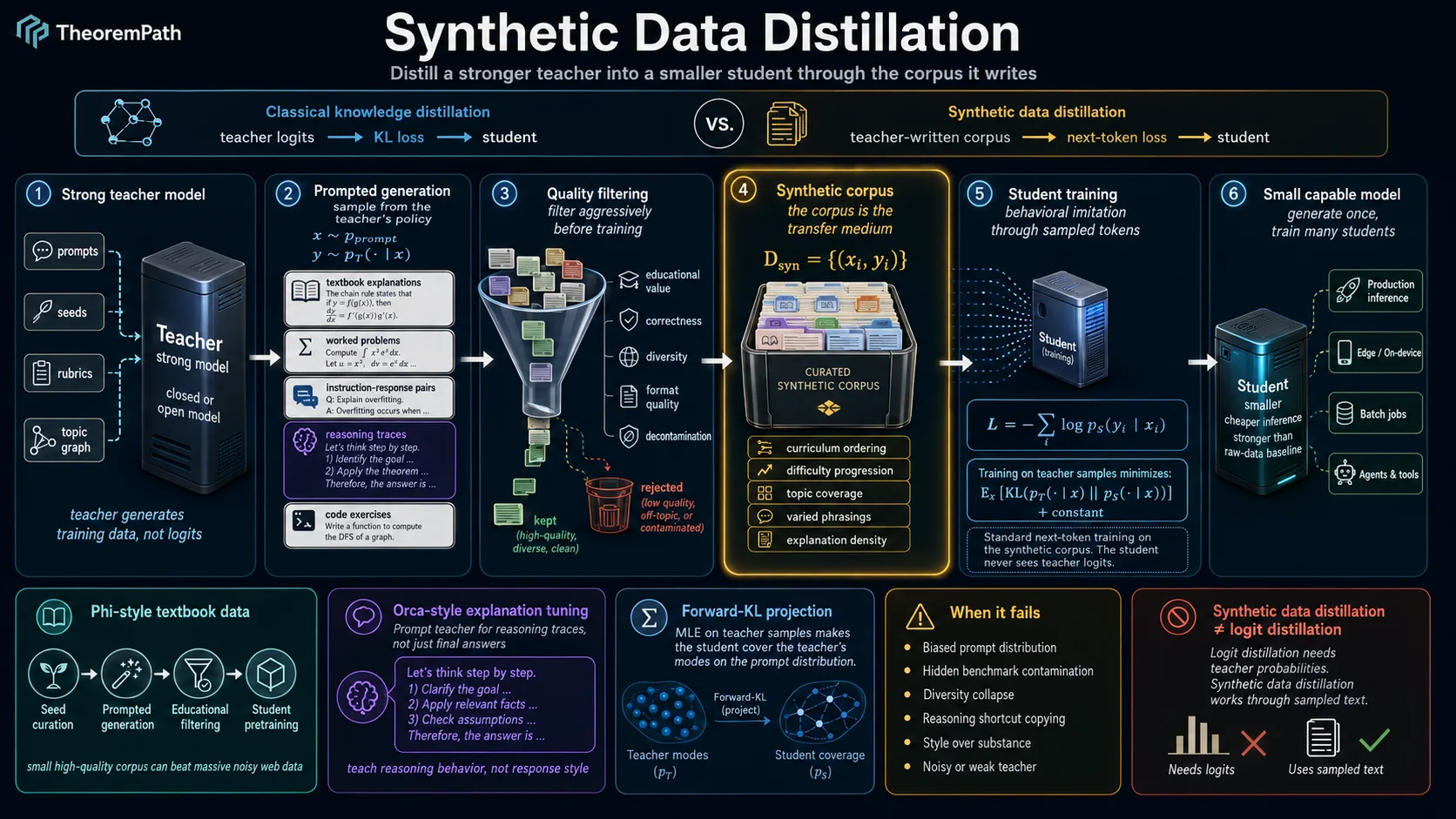
Classical knowledge distillation matches the student's output distribution to the teacher's at the logit level. This requires joint access to teacher and student during training and assumes the teacher's full probability vector is available.
Frontier small-model recipes of 2023-2025 use a different pattern. Instead of matching soft targets, they ask the teacher to write new training data, then train the student on that data with the standard next-token objective. The teacher's knowledge reaches the student only through the text corpus it wrote, not through its logits. The pipeline is decoupled: generate once, train many times, and any student architecture works.
Phi-1 (Gunasekar et al. 2023, "Textbooks Are All You Need", arXiv:2306.11644) trained a 1.3B code model on roughly 7B tokens: about 6B of "textbook quality" code filtered from the web, plus 1B of synthetic textbook-style material and Python exercises generated by GPT-3.5. Phi-1 obtained HumanEval pass@1 of 50.6%, beating much larger contemporaneous code models trained on raw web data. Phi-1.5 (Li et al. 2023, arXiv:2309.05463), Phi-2, Phi-3 (Abdin et al. 2024, arXiv:2404.14219), and Phi-4 (Abdin et al. 2024, arXiv:2412.08905) extended the recipe to general reasoning. Orca (Mukherjee et al. 2023, arXiv:2306.02707) and Orca 2 (Mitra et al. 2023, arXiv:2311.11045) showed that distilling the teacher's full explanation traces — rather than answers alone — transferred reasoning behavior to small students that imitation of final answers could not reach.
The bet is sharp and testable: for a fixed student-compute budget, a smaller high-quality synthetic corpus beats a larger noisy web corpus.
Two Axes of Distillation
Logit-Matching Distillation
Standard Hinton-style distillation. Teacher and student both process the same input ; the student is trained to match the teacher's soft output distribution via a temperature-scaled KL loss. Requires access to teacher probabilities and typically trains teacher and student on the same input distribution.
Synthetic Data Distillation
The teacher generates a dataset by sampling from its own policy (possibly conditioned on prompts, seeds, or rubrics). The student is trained on with the standard next-token cross-entropy loss, never seeing the teacher's logits. All information about the teacher flows through the sampled tokens.
The two are not mutually exclusive. In practice, modern pipelines combine synthetic-data distillation for the bulk of training with targeted logit-matching or preference-based signals in later stages (process reward models, RLAIF). This page focuses on the synthetic-data axis.
The Phi Recipe
Textbook-Quality Synthetic Corpus
A training corpus constructed by a strong teacher LLM under generation constraints chosen to maximize pedagogical value per token: clear explanations, worked examples, varied phrasings of the same concept, monotone difficulty progressions, and explicit prerequisite chaining. Coined by Gunasekar et al. (2023) for the Phi-1 training data.
Phi-1's pipeline, reconstructed from the paper:
- Seed curation: a small set of high-quality documents (textbook snippets, algorithm exercises, filtered code) forms the style anchor.
- Prompted generation: GPT-3.5 is prompted to produce new documents that imitate the style and pedagogical shape of the seeds while covering specified topics. Topic diversity is enforced by sampling topic lists from a curriculum graph rather than letting the teacher freely choose.
- Filtering: generated documents are filtered by a classifier trained to score "educational value". Low-score documents are dropped.
- Student training: the student (for Phi-1, a fresh 1.3B transformer) is trained from scratch on the combined corpus (filtered web data plus the synthetic corpus) with standard next-token loss.
The Phi-1.5 and later reports extend this to general knowledge, reasoning, and conversation. Phi-3 and Phi-4 add heavy use of synthetic instruction and reasoning traces alongside the textbook-style base corpus.
The Orca Recipe: Explanation Tuning
Orca (Mukherjee et al. 2023) addressed a narrower problem: imitation-tuned small models often learn the style of the teacher (response shape, length, tone) without the reasoning. Training Vicuna-7B on ChatGPT responses produced a model that sounds like ChatGPT on easy questions but fails on hard ones because it never saw the teacher's step-by-step derivations.
Explanation Tuning
Instead of training the student on pairs where is the teacher's final answer, train on where is the teacher's full chain-of-thought derivation elicited via system prompts like "explain like I'm five", "step by step", or "justify each step". The student is supervised on the trace, not the final answer.
Orca trained Llama-13B on roughly 5M instruction-response traces from ChatGPT plus about 1M traces from GPT-4, prompted through a bank of hand-crafted system messages (16 in the paper) that request formats such as step-by-step reasoning, recall-then-generate, and careful self-critique. The result closed much of the gap between small imitation models and the teacher on BigBench-Hard and AGIEval.
Orca 2 (Mitra et al. 2023) added a "cautious reasoning" step where the teacher was prompted to first decide which reasoning strategy applies, then execute it, so the student learns strategy selection as part of the trace.
Why This Can Exceed Vanilla Imitation
Synthetic-Data Distillation as a Lower-Variance Target
Statement
Training the student by maximum likelihood on samples with and minimizes, in expectation,
up to a constant. The student's limiting policy is therefore the forward KL projection of the teacher onto the student's function class. When the student has enough capacity to represent , the bound is tight and the student recovers the teacher distribution on the prompt set.
Intuition
Sampling from the teacher and training the student on those samples is a Monte Carlo estimate of the teacher's expected log-likelihood gradient. Each sampled is a noisy but unbiased signal about the teacher's full distribution. Over a large corpus, the student sees the whole conditional structure.
This matters because the forward KL is mode-covering: the student is penalized for putting low mass where the teacher puts mass. A student trained on synthetic teacher outputs must cover all modes the teacher does, not just the most common one.
Proof Sketch
The MLE objective is with . By the law of large numbers this converges to , the cross-entropy. Decompose as . Minimizing over only affects the second term.
Why It Matters
Two consequences. First, this is the right objective when you want the student to behave like the teacher on the prompt distribution. Second, the fidelity of the student is bounded below by the effective number of teacher samples (bias-variance of MLE), not by the teacher's logits, so good synthetic corpora can substitute for logit access. This is why closed-model distillation through API sampling (no logit access) works at all.
Failure Mode
The result assumes and i.i.d. prompts from . Real synthetic pipelines violate both:
- Biased prompt distribution. The prompt set used to query the teacher is chosen by the pipeline author; the student ends up matching the teacher only on that slice.
- Filtered outputs. Rejection sampling on quality filters produces , not . The student learns a filtered teacher, which can be sharper or duller than the raw teacher depending on the filter.
- Temperature and sampling parameters. If is sampled at (low temperature), the student sees a sharpened teacher; if sampled with nucleus or top-k, the student never learns the tail.
In practice the student matches a conditioned teacher, which is usually what the pipeline designer wants but is not the raw the theorem describes.
The vanilla imitation ceiling (student bounded by teacher) is a corollary when the filter is trivial. Evol-Instruct (Xu et al. 2023, WizardLM, arXiv:2304.12244), weak-to-strong generalization (Burns et al. 2023, arXiv:2312.09390), and process reward models (Lightman et al. 2023, "Let's Verify Step by Step", arXiv:2305.20050) all exceed the ceiling by changing the sampling distribution, not by changing the loss.
When the Recipe Works
The teacher is substantially stronger than the student. Phi-1 used GPT-3.5 to generate data for a 1.3B student. Orca used GPT-4 (and ChatGPT) to generate traces for a 13B Llama student. If the teacher-student gap is small, synthetic data adds little.
Quality filtering is aggressive. Phi and Orca report dropping large fractions of generated data based on classifier or heuristic filters. Without filtering, the synthetic corpus inherits the teacher's distribution including its noise floor.
Diversity is enforced by the prompt design, not trusted to the teacher. Letting the teacher freely choose topics produces heavy head bias (common topics dominate). Phi seeds generations from an explicit topic graph. Orca samples from 16 hand-crafted system messages. Both treat topic diversity as a pipeline invariant, not a teacher behavior.
Evaluation is decontaminated. Any benchmark answer that appears in synthetic data invalidates the benchmark for that model. N-gram and embedding decontamination is standard in the Phi and Orca pipelines.
Evaluation and Audit Checklist
Synthetic-data distillation needs a stricter audit than ordinary supervised training because the training set is produced by a model that may already know the benchmark. Separate these checks before reporting results:
| Check | Concrete evidence | Failure it catches |
|---|---|---|
| Decontamination | N-gram and embedding match against test items, prompts, and solutions | Benchmark leakage through memorized public examples |
| Prompt coverage | Topic histogram, difficulty histogram, source-task map | A corpus that overrepresents easy or fashionable tasks |
| Diversity | Near-duplicate rate, template clustering, paraphrase clusters | Many synthetic examples with the same latent problem |
| Reasoning transfer | Process-level evals, held-out hard problems, verifier traces | Students copying style without learning strategy |
| Teacher dependence | Teacher-family ablation or weaker-teacher control | Gains caused by one teacher's quirks rather than the recipe |
| Live holdout | Fresh tasks written after corpus generation | Hidden contamination that static test sets miss |
This is why "trained on synthetic data" is not enough information. The scientific object is the full pipeline: prompt source, teacher, sampling settings, filters, deduplication, decontamination, curriculum order, and the student objective. Change any one of those and the result can change.
What Counts as Real Evidence
A strong synthetic-distillation result has at least one evaluation that the teacher-data pipeline could not have memorized. Good examples include fresh private tests, live coding tasks written after generation, hidden reasoning benchmarks, or domain-specific expert review. Public benchmark gains are still useful, but only after the report shows the generated corpus was searched for test-item overlap.
The most convincing ablation is not "with synthetic data versus without." It is a four-way split:
- Same student on raw web data.
- Same student on filtered human-written data.
- Same student on synthetic data without filtering.
- Same student on synthetic data with the full filtering and curriculum.
That split tells you whether the gain came from synthetic generation itself, from the filtering/curriculum pipeline, or simply from having cleaner data. To isolate curriculum order separately, add one more condition that keeps the data fixed and changes only the order.
When the Recipe Fails
Hidden contamination. The teacher has seen public benchmarks during its own training. When asked to generate "a reasoning problem about X", it sometimes reproduces benchmark items verbatim or with trivial paraphrasing. Phi-3 and Phi-4 reports detail the decontamination they apply; not all groups are as careful. Suspect strong benchmark numbers that were not checked against the generation corpus.
Diversity collapse. A teacher asked for "N new problems like these seeds" often produces N variations of a small number of latent templates. Downstream students then overfit the templates and fail on genuinely new items. This is the model collapse mechanism operating at the single-generation level, not just across recursive generations.
Reasoning shortcut copying. Orca 2 documented this. If the teacher sometimes guesses correctly without full reasoning (lucky shortcut), the student learns the shortcut as a valid strategy. Subsequent hard problems where the shortcut fails catch the student but not the teacher.
Style over substance. A student trained on teacher responses can learn response shape (confident tone, bulleted structure, characteristic openings) without the underlying reasoning. Evaluating only for "does it sound right" misses this. Orca's motivation was this exact failure mode in earlier Vicuna-style imitation.
Common Confusions
Synthetic data distillation is not the same as knowledge distillation
Classical distillation matches logit distributions. Synthetic data distillation matches sampled tokens. The former needs white-box access to the teacher. The latter works through any API that returns strings. Papers sometimes use "distillation" for both; read carefully to see which is meant.
Textbook-quality is a pipeline property, not a token property
"High-quality data" is not a statement about individual tokens. A corpus is textbook-quality because of its structure: topic coverage, difficulty progression, explanation density, decontamination. Two strings with the same tokens can differ in pedagogical value because of where they sit in the curriculum. Measuring quality per-document misses the ordering property that matters.
Explanation tuning is not chain-of-thought prompting
Chain-of-thought (Wei et al. 2022) is an inference-time prompt pattern that elicits reasoning from a trained model. Explanation tuning is a training-time recipe that supervises the student on the teacher's reasoning traces, so the student produces reasoning by default without needing CoT prompts. The two compose but are distinct.
Beating the teacher does not contradict the imitation ceiling
Pure imitation of by MLE is bounded by the teacher on the training prompt set. But if the pipeline filters, rewrites, or combines teacher outputs, or uses per-step verification to discard wrong reasoning, the effective target distribution is no longer and the ceiling does not apply. Reports of "student exceeds teacher" nearly always involve such filtering or RL-style signal, not vanilla MLE.
Canonical Example
Phi-1: 1.3B beats larger code models with a smaller corpus
Phi-1 was trained on roughly 7B tokens: about 6B of "textbook quality" code filtered from the web and 1B of GPT-3.5-generated synthetic textbooks and exercises. The Llama 1 7B reference model used roughly 1T web tokens, two orders of magnitude more. Phi-1 reports HumanEval pass@1 of 50.6% versus 10 to 30% for contemporaneous code models in the 7B to 15B range (StarCoder 15B reached roughly 33.6%, Replit-code-v1 3B roughly 21.9%). The recipe is not that the teacher was smarter, it is that the student never had to learn to read bad code.
Caveat: HumanEval is a small benchmark that is close to the pedagogical shape of the synthetic corpus. Broader evaluations (MBPP, HumanEval+, deeper live coding) show a smaller gap. The Phi recipe favors benchmarks that look like textbooks because the training data looks like textbooks.
Exercises
Problem
A pipeline queries the teacher only with prompts drawn from distribution . Suppose the deployment distribution for the student is . What happens to the KL objective, and what practical failure mode does this create?
Problem
A "Best-of-K" synthetic pipeline queries the teacher K times per prompt, keeps only the sample with the highest teacher-probability under a secondary scorer, and trains the student on the kept sample. Show that the effective target distribution is no longer , and describe the direction in which it is sharpened or duller.
References
Canonical:
- Gunasekar et al., "Textbooks Are All You Need" (2023, arXiv:2306.11644). Phi-1, data pipeline Sections 2-3, HumanEval results Table 1.
- Li et al., "Textbooks Are All You Need II: phi-1.5 Technical Report" (2023, arXiv:2309.05463). General-reasoning extension of the Phi recipe.
- Mukherjee et al., "Orca: Progressive Learning from Complex Explanation Traces of GPT-4" (2023, arXiv:2306.02707). Explanation tuning, meta-instruction bank, Sections 3-4.
- Mitra et al., "Orca 2: Teaching Small Language Models How to Reason" (2023, arXiv:2311.11045). Cautious reasoning, strategy selection.
Current:
- Abdin et al., "Phi-3 Technical Report" (2024, arXiv:2404.14219). Sections on synthetic data curation and decontamination.
- Abdin et al., "Phi-4 Technical Report" (2024, arXiv:2412.08905). Heavy synthetic-reasoning corpus, post-training pipeline.
- Xu et al., "WizardLM: Empowering Large Language Models to Follow Complex Instructions" (2023, arXiv:2304.12244). Evol-Instruct as a way to exceed the vanilla imitation ceiling by complexifying prompts.
- Zhou et al., "LIMA: Less Is More for Alignment" (NeurIPS 2023, arXiv:2305.11206). Complementary evidence that small, carefully curated instruction data rivals large noisy SFT.
- Burns et al., "Weak-to-Strong Generalization" (2023, arXiv:2312.09390). When a stronger student can exceed a weaker teacher's behavior.
Next Topics
- Reasoning Data Curation: the verification and filtering side of synthetic reasoning pipelines.
- Curriculum Learning: how the pedagogical ordering in a synthetic corpus affects training dynamics.
- Synthetic Data Generation: the generic pipeline view, including diffusion-based image synthesis and model-collapse analysis.
Last reviewed: May 27, 2026
Canonical graph
Required before and derived from this topic
These links come from prerequisite edges in the curriculum graph. Editorial suggestions are shown here only when the target page also cites this page as a prerequisite.
Required prerequisites
2- Knowledge Distillationlayer 3 · tier 2
- Synthetic Data Generationlayer 3 · tier 2
Derived topics
2- Reasoning Data Curationlayer 5 · tier 2
- Curriculum Learninglayer 2 · tier 3
Graph-backed continuations